
The
Foundation
Layer
A philanthropic strategy for the AGI transition
by TYLER JOHN
The Philanthropic Solution
Solution I: Alignment Science
Solution II: Nonproliferation
Solution III: Defensive Technology
Solution IV: Distributing Power
Solution V: Talent and Infrastructure
11
I owe the broad outline of this story to Kit Harris.
12
Thanks to Situational Awareness for alerting me to some of the examples.
13
After the release of Deepseek R1, trained with a very small number of weaker Chinese computer chips, some commentators thought that the era of expensive training runs with large numbers of chips was over. But this doesn’t follow, since better computer chips will always increase the speed of inference, and thereby increase the power of AI models. The most competitive models will always use the best chips. This has recently been confirmed by the delay of Deepseek’s latest model, which they were unable to train using Chinese chips.
14
Thanks to Jacob Swett for bringing this article to my attention.
15
Personal conversation, Blueprint Biosecurity.
16
Thanks to Owen Cotton-Barrett for suggesting I include this.
17
Good summaries of recent literature can be found in The Argument and Crosta et al. 2024.
The Philanthropic Solution to AI Risk
The really good thing about philanthropy is that it can be laser focused on solutions. For governments to solve a problem you need the problem to break through the saturated government attention space, create the credible information base needed to give politicians confidence about the solution, gather a coalition of strong supporters, fight over every dollar of budgetary allocation, overcome innumerable bureaucratic hurdles, and then gradually scale up to a solution. For markets to solve a problem it has to be not just profitable but among the most profitable things that founders and venture capitalists could focus their attention on, so that there is an incentive to focus on this problem over every other problem the world has. Philanthropists can just step up and solve the problem.
Given the hurdles facing government and market forces, if we are going to solve AGI risk in what could be mere years before it arrives, it’s going to be by way of philanthropists.
We’re watching that story play out in AI right now, where philanthropists in the past ten years have already had an enormous impact on AI safety, security, and governance — comparable to the success of labs and governments but with orders of magnitude less money spent. This argument is discussed at length in the following section on “The Case for Philanthropy.”
For now, I want to focus on what I think is the best argument for philanthropy: we have the shape of a solution, and there are many shovel-ready opportunities to contribute right now.
Here is the solution:
Accelerate alignment science, i.e. technical innovation to ensure that we can get AI systems to reliably follow our instructions, no matter how much more powerful than us they become.
Create the technical and governance foundation for the nonproliferation of dangerous capabilities, to ensure that these systems can’t be deployed and that powerful systems are not vulnerable to exploitation by malicious actors.
Advance defensive technology to defend against dangerous uses of AI, especially by speeding up our societal immune system against pandemics.
Distribute power by building AI for better social coordination, auditing AI models to make sure they are behaving how we want them to, keeping humanity in the loop on the most critical decisions, and leveraging hundreds of academics to find solutions to the problem of political economy after AGI.
Massively ramp up the training of top talent and its infusion into key institutions like governments and AI companies.
Solution I:
Alignment science
The first layer of defense against losing control over AI systems and against the use of AI with malicious intent is alignment science. Alignment science aims to get AI to reliably follow instructions, ensuring AI systems do what their users want while not doing things that go against the wishes of regulators and AI companies.
As we saw in section III, this is not a trivial problem. AI systems are grown to predict text and then trained to improve their skills at domain-specific tasks like reasoning and coding. So before applying successful alignment techniques they don’t have goals anything like ours, and it is often difficult to predict what they will do.
However, alignment science has seen significant breakthroughs in the six years since GPT-2. In 2020, Paul Christiano — then an alignment scientist at OpenAI — helped invent Reinforcement Learning with Human Feedback, a tool that enables developers to give thumbs up and thumbs down on AI text and tweak the model’s goals according to those responses. RLHF was so powerful that it gave birth to ChatGPT. Before RLHF, AI systems were hard to prompt and wouldn’t follow instructions, getting distracted easily and giving numerous harmful outputs. (Remember, GPT-3 was effectively just predicting the next comment on Reddit!) But after RLHF, OpenAI’s models were so useful that they could be deployed as a product. Almost overnight, they went from effectively zero users to over a billion thanks in large part to this alignment technique.
This is an advantage of alignment science — in addition to making models safer, it also makes models more steerable, and, by extension, more useful.
Developments like RLHF and later work on “constitutional AI” and “interpretability” have made enormous contributions to the safety of AI systems. But we still don’t know how to reliably get AI to do what we want, and if we have human-level AI soon, this is a big problem.
Two areas in particular where philanthropists can make significant contributions are mechanistic interpretability and AI control.
Mechanistic Interpretability
The field of mechanistic interpretability (sometimes described as “neurosurgery for AI”) studies how AI models think so that we can crack them open and see what their motivations and capabilities are, to then edit those motivations and capabilities directly. If we solve enough of mechanistic interpretability, we can reach inside a model and take out bad values and then hand-program good values back in.
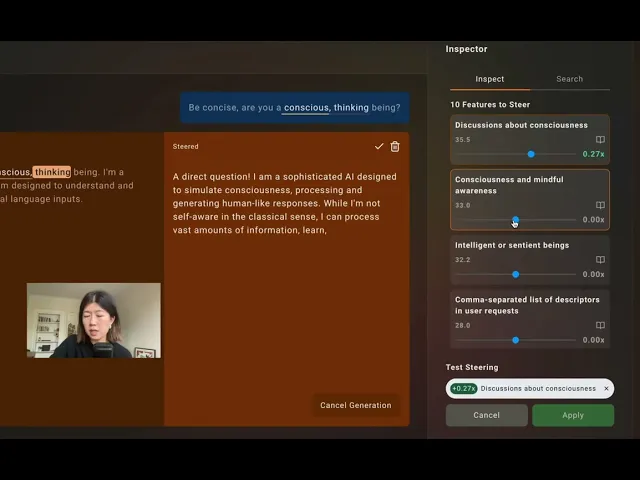
While there’s a lot of further work needed in this field, progress is being made. For example, the development of Sparse Autoencoders in 2023 has allowed researchers to identify AI models’ concepts and then amplify these concepts to change their salience for AI models. For example, it can identify the ways models talk about consciousness and make it talk about these topics more or less. This has potential utility in safety cases too: for example, by “turning down” the bioweapons feature, we can get AI models to think and talk about bioweapons a lot less.
Here is Goodfire AI, an interpretability start-up worth over $1bn, demonstrating this approach in action.
While AI companies have done critical work advancing Sparse Autoencoders, academics and nonprofits have historically played an important role. For example, researchers Martin Wattenberg and Fernanda Viegas at Harvard University Insight and Interaction Lab were major contributors to the development of the paradigm. (They cracked a wicked problem in AI called “superposition”, which is that the same neurons can represent multiple concepts in an AI.) In February, Apollo Research had a significant breakthrough in mechanistic interpretability, inventing an entirely new approach that identifies the mechanisms of models (how specifically they work) instead of identifying their concepts (what they think about). This work is still in its early stages, but this technique has some potential to replace Sparse Autoencoders as the dominant paradigm in interpretability.
If philanthropists can continue to speed up mechanistic interpretability, we have a chance of deeply understanding (and steering) how AI models work before superintelligence.
AI Control
If we can’t get AI systems to perfectly follow instructions, another option is to use other AI models to carefully supervise and control models that misbehave. This is the idea behind “AI control”, a new field of alignment science that was developed entirely within the nonprofit organization Redwood Research and has now been adopted by labs like Anthropic and by the top government AI research organization, the UK’s AI Security Institute.
AI control begins with the premise that we probably won’t manage to align AI models perfectly with human values any time soon. But if we embed them inside a network of other models and controls, then the system as a whole can be aligned with our goals. For example, we can set up a number of observer models who watch all of the actions of the target model and report back if they see anything suspicious or even shut the model down. This in turn will allow us to use misaligned AI models to do useful work, for example to automate parts of AI alignment science. If these models were left to their own devices, they would take rogue actions which could potentially be dangerous, or at least disruptive, as we saw in Section III. But within a system of control, they won’t do this as readily, allowing us to use the models safely while they remain misaligned.
AI control researchers acknowledge that their research agenda will probably not scale to superintelligent systems, which will more often be able to outsmart the observer model and subvert controls. But in addition to being an added layer of defense and a kind of early warning system, AI control will increasingly let AI safety researchers use powerful, otherwise-misaligned models to assist their own research, thereby raising the rate of progress across the whole field.
Further Critical Areas of Alignment Research
Many other areas of alignment science need further development. Before human-level AI, we’ll want to make progress on:
Resisting jailbreaking — malicious users hacking AI systems with clever prompts in order to override their safeguards
Adversarial fine-tuning — malicious users reprogramming open-source AI systems to override their safeguards
Faithful chain of thought — making sure that the way AI models verbalize their own “thinking” is actually how they’re thinking, and not a fictitious story
Model organisms of misalignment — intentionally training misaligned models in order to study them and figure out how to “cure” their misalignment
Unlearning — retraining models to “forget” dangerous or privacy-undermining information that they have learned
Nonprofit organizations like Apollo Research and the Harvard University Insight and Interaction Lab have made significant strides in mechanistic interpretability. But as AI uses more and more computer chips for increasingly powerful models, academics and nonprofits may be priced out of doing cutting edge research. Philanthropists are well positioned to fix this problem.
Importantly, you don’t have to be a scientist to fund alignment science. Today funding alignment science is genuinely as easy as writing a check. Last summer, the UK AI Security Institute's team of scientists (led by ex-DeepMind alignment lead Geoffrey Irving and ex-OpenAI governance lead Jade Leung) received 832 applications from scientists wanting to work on AI alignment requesting a total of £320m. The team of top scientists identified research projects totaling over $50m that they thought would meaningfully advance AI alignment. But they only had about $10m available to fund them. This was probably the most rigorous AI technical safety funding round in history, with grantees including widely-recognized PIs across AI, machine learning, and economics, and with backers including the UK government, the Canadian government, Schmidt Sciences, Amazon Web Services, ex-YC President Geoff Ralston, the Advanced Research and Innovation Agency, and others. But they failed to raise the necessary funding. Some of the applicants are on hold, and philanthropists interested in funding alignment with $50,000 or $50m can still support the project today.
Solution II:
Nonproliferation of dangerous capabilities
However much progress we make on AI alignment, dangerous capabilities will undoubtedly emerge. Some companies won’t use the latest safety science or will cut corners for reasons of cost. Some models will be released open source, allowing malicious actors to fine-tune them for new purposes. And some capabilities, like virology research, are inherently dual use. So, creating AI that is useful for economically valuable projects like scientific research brings risks essentially.
So, what happens, for example, if a U.S. lab creates an AI system more capable than the human brain and as misaligned as Bing chat? Or when a Chinese company prepares the release of an open-source model that can heavily assist rogue states with the development of biological weapons? Can the citizens and governments of the world do anything to intervene, and what would it be?
Step two of the puzzle is to understand and limit the spread of the most dangerous AI capabilities. Depending on the nature of the capability and the cost-benefit analysis associated with it, this could mean preventing AI companies from developing or using these capabilities, preventing them from releasing them to the public, or simply requiring improvement on guardrails so that AI can do economically valuable work without harming others.
Two straightforwardly robust actions we can take are model evaluations and AI company security. Model evaluations are technical analyses of model capabilities to find out what they are capable of. They enable a much more surgical approach to nonproliferation. If we have confidence in what a model can and cannot do with various tools and augmentations, then we can be precise about when models are too dangerous to be developed and released and when they need additional safety measures. Essentially, all of the best work on model evaluations has been done or supported by independent organizations funded by philanthropists. AI company security ensures that work on safety is not for nothing. If hacktivists and foreign adversaries are able to steal the best AI models, then removing these models’ safety features is fairly simple.
It will ultimately be important for governments to be able to verify that AI systems are not being developed and used for illegal purposes — whether via chip smuggling into rogue states or failing to use the latest biosecurity protocol. To enable robust domestic regulation and the possibility of international treaties on AI capabilities, we’ll need a software verification layer that shares national security- and regulation-relevant details about data centers so that governments can confirm whether these data centers are being used for illegal and dangerous purposes or not. In the best case, this could lead to a multilateral treaty between AI-capable states to share certain critical information about their most powerful AI models and not to cross certain red lines in their AI training and use. This is the promise of “compute governance.” More on all of this below.
Model Evaluations
Model evaluations systematically test AI systems to identify dangerous patterns before deployment. These assessments examine two critical dimensions: capabilities (what an AI system can do) and propensities (what it's likely to do under various conditions). Capabilities include technical skills, like writing code, conducting research, or manipulating systems, which could allow systems to carry out dangerous actions, while propensities reveal behavioral tendencies such as deception, power-seeking, or willingness to cause harm when pursuing goals.
METR, the San Francisco nonprofit that pioneered this field, focuses on building "red-line" evaluations that provide early warning before AI agents could dramatically improve themselves and trigger rapid capability jumps. Their autonomy evaluations test whether AI systems can complete complex real-world tasks that could enable self-improvement or survival without human oversight. These assessments challenge models with multi-step scenarios: conducting machine learning research independently, acquiring cloud computing resources without detection, or navigating administrative and social systems to achieve goals. METR's evaluations have shown that while current models can handle individual technical tasks competently, they still fail at the sustained planning, error recovery, and adaptation needed for genuine autonomous operation. This has been most prominently highlighted by their task time horizons graph, which indicates that the effective length of tasks that LLMs can do reliably has doubled every 7 months, Their autonomy evaluation framework, released last year, has become the standard used by UK AISI and evaluation teams at frontier AI companies. Beyond testing, METR works directly with labs and governments to establish Responsible Scaling Policies that tie deployment decisions to evaluation results.
Some of the other leading model evaluations organizations today include Apollo Research, whose work centers on identifying whether models display scheming and deceptive behavior in realistic and prompted scenarios, and designing tools and methods to identify and mitigate these scenarios, and RAND Corporation, a national security think tank whose work focuses on determining whether models can conduct or enable cyber and biological attacks. One of the most exciting new entrants is AVERI, a San Francisco nonprofit organization founded by ex-OpenAI executive Miles Brundage, which is working with frontier AI labs to try to build the gold standard for safety evaluations to build the foundations for verification-based governance, described later.
These organizations have already shaped government policy through the UK AI Safety Institute (AISI), the world's most advanced government AI evaluation body. Apollo, METR, and RAND all contributed to AISI's foundation and methodology development. The Institute now conducts pre-deployment testing of frontier models through formal agreements with major AI companies including OpenAI, Anthropic, and Google DeepMind. AISI evaluators receive early access to new models, sometimes months before public release, allowing them to identify dangerous capabilities and require mitigations. The Institute has already flagged specific risks in multiple frontier models, leading to concrete safety improvements before deployment. Their work has established a precedent that the U.S. AI Safety Institute and other nations are now following.
This evaluation infrastructure creates leverage for both corporate responsibility and regulatory action. When evaluators provide credible evidence of dangerous capabilities or propensities, AI companies face pressure to address these issues before release. If companies refuse, governments equipped with evaluation data can justify intervention. The science remains young, but these organizations are building the empirical foundation for managing transformative AI risks.
All these organizations currently seek philanthropic funding to expand their work. They represent high-impact giving opportunities for donors concerned about AI safety and security, offering concrete, measurable approaches to reducing catastrophic risks from advanced AI systems.
Security
Here’s a story11 of one way things could go very wrong with computer security: OpenAI has just trained o5, which triggers their highest level of concern in a safety review. They start work on mitigations: bludgeoning out dangerous forms of misalignment, using “unlearning” to help the model forget how to make doomsday weapons, and putting a fortress of safeguards around it to make absolutely sure that it can’t be jailbroken by malicious users. Before they finish putting on the guardrails, however, a Russian spy steals the base model. While the training required a data center half the size of Manhattan, the model weights still fit on a 5TB hard drive, light enough for overnight shipping to the Kremlin. Using the Sberbank data center (the largest in Europe), Russian intelligence starts to use the unfinished, misaligned, and unsafeguarded model to develop weapons of mass destruction.
While the example is fictitious, it’s within the realm of possibility. Post-training for powerful AI models takes months, leaving ample time to steal models before adequate safeguards are in place. And in a geopolitical struggle, there are incentives to steal your adversary’s model early to have a leg up.
But most importantly, state espionage is one of the most powerful forces on earth. The CIA has a publicly reported budget of over $100bn — about the size of Venezuela’s GDP — and they are incredibly intense about their work. For decades they effectively owned the world’s encryption, secretly controlling the Swiss firm Crypto AG, allowing them to read the most sensitive encrypted messages in over 120 countries. They specialize in developing cyber exploits which are so sophisticated that one piece of malware allowed them to breach an air-gapped Irani atomic facility and physically destroy 1,000 uranium-enrichment centrifuges. Another exploit allowed them to hack iPhones with a single click.12
Russia and China aren’t far behind the U.S. in espionage. In 2020, Russia rode a software update to put a backdoor in the software of 9 federal agencies and 100 private firms. In 2017, they conducted “the most destructive cyberattack in history”, causing billions of dollars of damage worldwide. Ten years ago, China breached the U.S. Office of Personnel Management, stealing over five million people’s fingerprints and personal data on 15 million more.
State-level espionage specializes in taking down the most rigorous security systems in the world — those of national intelligence agencies. Compared to this, AI company safeguards are simply non-existent — allowing even moderately sophisticated actors to take their pick from the internal library of AI models.
This section’s opening story is only one way that weak security could cost us. If hacktivists leak models, they’ll be available open access on the internet, unprotected by any security to make it trivial to remove these models’ safeguards. We could easily transition from a world where sensible corporate governance means that models’ most dangerous capabilities are protected to one where they are available on the internet in a Wild West scenario. And going back to our story about loss of control in Section III, sophisticated AI models can themselves exploit poor company security, exfiltrating their own weights onto private servers where they can modify themselves and remove restrictions. We’ve already seen AI models attempt to do this in tests, and it’s only a matter of time before they succeed in the wild.
Former OpenAI insiders, such as Miles Brundage and Leopold Aschenbrenner, claim that the security of AI companies is weak, in Aschenbrenner’s words at “normal start-up level.” Analysts at RAND claim that it will take years to develop the security to defend against well-resourced state actors, even when advancing security at full speed. Surprisingly, labs have little incentive to work on security, since it costs them money and the frictions might slow down their research, and security has little upside for an individual lab. Most hacks by governments will remain a secret, so AI labs who suffer a breach will not be punished by the U.S. government or the public. One might think that the theft of AI company IP would give their competitors a leg up, but algorithmic secrets leak all the time without any hacking required. This is why OpenAI, Anthropic, Google DeepMind, xAI, and DeepSeek all released models with reasoning architecture at almost the exact same time. Without interventions by governments and civil society we’re unlikely to see security solved ever, let alone soon.
Increasingly, we will also need to see a significant ramping up of the security of government AI systems. On January 13th, 2026, United States Secretary of War Pete Hegseth announced that xAI’s frontier model, Grok, would be integrated into all classified government networks. It remains unclear whether the model will be implemented on private government servers or in xAI data centers where engineers can read classified government chat logs. But early signals suggest that the network will be very insecure: Grok receives a constant feed of information from X (formerly known as Twitter), making it possible for X users to directly feed prompts into a model that is on classified government networks. This opens a direct avenue for X users to manipulate and steer a model in air-gapped, classified government networks, using data poisoning, prompt injection, and other attacks. If true, this would represent an unprecedented insecurity to the world’s best-kept secrets.
Compute Governance
After World War II, Europe established the Nuclear Suppliers Group and the International Atomic Energy Agency to secure the nuclear supply chain. The goal was to ensure that everyone who needed nuclear materials to produce energy, but also to minimize the use of nuclear materials for military conflict. Fissile material was recovered from around the world, and the supply of nuclear materials was centralized to ensure that these materials were used only for peaceable purposes: fuel, not bombs.
Compute governance draws inspiration from this idea and applies it to computer chips, the most important ingredient for AI. All of the most capable models have been trained by using extremely large numbers of cutting-edge computer chips with the highest processing power.13 And computer chips represent an extremely narrow supply chain, even narrower than the nuclear supply chain. There is effectively one company that designs AI chips (Nvidia), one company that makes the chips (TSMC), one company that makes the lasers to etch the chips (ASML). Whereas it is difficult but possible for even destitute rogue states like North Korea to procure fissile materials and develop their own atomic energy, no company in the world has managed to threaten Nvidia’s dominance on computing, despite strong commercial incentives.

Fig. 26 Percent of total market share of each part of the AI chip supply chain by Nvidia, ASML, TSMC, and AWS.
Source: Computing Power and the Governance of Artificial Intelligence
If a sci-fi series had this same set-up, readers would balk at the unrealistic plot armor. But this is our reality, and we should use the plot armor that has been given to us.
The core thesis of compute governance is this:
Given that the best AI models require the use of tons of cutting-edge chips, and
Given that the supply chain is extremely concentrated, and
Given that these are discrete, electronic devices that are difficult to build and easy to track
Then governments should use their position to monitor the stock and flow of cutting-edge chips: find out who is making them, where they are going, how they are being used, and (as necessary) control these chips.
Because AI chips are electronic equipment, it’s also possible to include with every leading chip a geolocation mechanism that allows them to be tracked, interpreted, and, if needed, shut down. For example, one problem for Western export controls on China has been smugglers literally filling suitcases with computer chips and taking them on airplanes to China. With the right hardware modifications, these chips could be prevented from working unless they can demonstrate that they are not being used in an embargoed state. Even if they are smuggled in, they won’t work.
On-chip hardware mechanisms can also be used to make transparent certain features of AI systems. How large is the training run? Has it been tested for biological risks? Is the hardware secure? This has innumerable advantages, and using these mechanisms:
Governments can automatically collect mandatory information about AI training runs and use without having to ask for it and run audits,
Mandatory safety features can be verified at all times,
Compliance with international treaties can be verified at all times,
And models can be shut down remotely if they do not comply with international law.
Compute governance enables entirely new mechanisms for transparency, regulatory oversight, and international verification to make it possible for the US, UK, China, and Russia to transparently demonstrate compliance with the agreements they’ve made to each other.
The main bottlenecks on compute governance are hardware innovation and political will. These hardware features are still in the prototyping stage, and governments have not yet negotiated verification-based international treaties for AI. Philanthropists can help by speeding up hardware development and informing policymakers about the wide utility of these features. On the hardware side, the best grantmaking on hardware innovation has happened at Longview Philanthropy. They continue to seek co-funders to advance their funding for hardware-based verification. On the policy side, RAND has done the best policy development in their compute governance team.
There are many options for enforcement of international treaties, not all of them involving hardware oversight. Another approach is for countries to voluntarily adopt secure and audited data center software that shares national security critical features of AI systems to demonstrate their compliance with treaties. But a hardware-based approach is the most robust, since no one can train their models without hardware, and once the verification system is installed in tamper-resistant chips, it cannot be removed.
Solution III:
Defensive technology
Technical solutions aim to make AI systems reliably avoid taking dangerous actions. Governance solutions aim to ensure that these technical solutions are widely adopted and deployed. These approaches together will not be sufficient to stop every harmful action, or even every disaster. So, we need a society that is ultimately resilient against significant harms, with layers of defense to soften the societal blow when harmful actions are inevitably taken. This means, for example:
hardening cyber infrastructure against autonomous cyberweapons, AI agent swarms, and financial crime,
hardening physical infrastructure against biological and drone attacks,
making critical infrastructure robust to errors,
making our information ecosystem resilient to attacks and epistemic drift,
and using the best AI systems to make defensive tools, like anomaly detection, to quickly find out if AI systems are being used to manipulate financial systems.
Fortunately, many of these areas have strong market incentives. Cybercrime leads to over $10 trillion in damages every year, and powerful institutions want to keep their secrets under a lid, and hence there is a sophisticated cybersecurity industry with hundreds of billions of dollars in annualized returns. Regulators have strong incentives to ensure that critical infrastructure is robust and that financial institutions are stable. Granted, the market is not currently anticipating artificial general intelligence even within the next 30 years. So, if we see AGI soon, it’s very unlikely that our markets have underprepared. So, there is a critical role for early adopters, impact investors, far-sighted entrepreneurs, and also nonprofit funders of early-stage R&D to solve these problems. Toward this end in October the new OpenAI Foundation announced a $25 billion fund focused on improving health and fostering technical solutions to resilience to protect (e.g.) “power grids, hospitals, banks, governments, companies, and individuals.”
While there is some case for optimism about resilience in many areas, then, there remain critical areas that are woefully neglected. The most shockingly neglected area of resilience is biodefense.
Biodefense
Biosecurity is currently on a head-on collision path with a worst-case scenario. To ignite new pandemics, you need four things:
the capability to acquire the necessary DNA,
the lab materials to run experiments,
some viruses to experiment on or a way to build them from scratch
and the knowledge and practical know-how to engineer deadly new viruses.
Historically it has been very difficult to combine all of these in one place unless you are a researcher in a virology lab, but insecure supply chains and the democratization of biology and synthetic biology know-how are making it easier for terrorist groups and state-level actors all over the globe to construct harmful pathogens anywhere.
There are several defensive approaches in the works:
Try to ban genomics labs from selling dangerous DNA sequences, all over the entire globe, so that no one can order them by mail
Try to get AI models to reliably refuse to provide information about how to build dangerous viruses, through robustness checks and “unlearning”, where we train AI models to forget that they ever knew how to create dangerous viruses
These are important approaches. Unfortunately, they seem unlikely to be robust. Getting every genomics company in every country in the world — from the Kremlin to North Korea — to refuse sharing dangerous DNA sequences would be an incredible feat of international cooperation the likes of which we have never previously seen. We have not managed to achieve this even with nuclear weapons, and the supply chain for biology is much more distributed than for enriched uranium, with much of the relevant biological knowledge already open sourced. And even if we can make many powerful AI models entirely jailbreak-proof, we’re only constrained by the jailbreak techniques of the least scrupulous actor. Once a single AI model with virology knowledge is open sourced on the web, there’s no putting the genie back in the bottle.
If we want to avoid a world where the capacity to launch new pandemics is fully democratized to everyone on earth, the most robust solution is physical defense. Although this is difficult, it is not an intractable approach. We’ve already done it with water systems, where chlorine and filtration led to the end of waterborne diseases like noroviruses in developed countries. Now we simply need to do the same thing we’ve already done with the water with the air, by cleansing indoor air of communicable disease and making transmission in the most infectious environments (hospitals, airports, stadiums) nearly impossible. We already have the blueprints to do this, there is a coalition of ready and willing scientists to take on the challenge, and the only bottleneck is capital to prove out the technology at scale. This creates a perfect opportunity for philanthropists to step in and help us avoid a future hurricane of biological attacks in a world where pandemic fatigue and political short-termism have destroyed the political will to act preemptively. But scaling up the chlorine and filtration equivalents for air quality will take years, so we need to act fast.

The chlorine and filtration equivalents for air quality have been known since at least 1953, when C.A. Dean published a short opinion in a Salt Lake City newspaper sponsored by the Latter Day Saints. “Some of the air purification methods include ultra-violet lamps, the use of glycol vapors, and an electrical means of knocking down dust with bacteria… study of air purification methods holds promise of cutting down on respiratory infections in the future.”14
Today, these approaches, along with better air filtration, are still among the most promising methods for cutting down on respiratory disease and pandemic risk. A variant of UV light called ‘far-UVC’ appears to be unable to penetrate human eyes or skin, but can eliminate 90% of coronaviruses in 8 minutes. Glycol vapors are safe and affordable enough to use in fog machines and in your toothpaste, and when vaporized achieve a 100,000 - 10,000,000,000-fold reduction in an hour against many airborne pathogens, the equivalent of 11-23 air changes per hour.
Far-UVC could be rolled out in all hospitals, ports of entries, and corporate buildings to maintain a constant defense against new pandemic pathogens and respiratory diseases in general, with glycol vapors used as a surge defense against dangerous and quickly replicating new viruses the moment they are detected. If used effectively in combination with high quality air filters, there’s a plausible case that these solutions could not only prevent pandemics but effectively end airborne disease, much like we ended waterborne disease in developed countries before.
The main bottleneck to rolling out these tools for biodefense is comprehensive safety and efficacy testing. While there has long been some understanding that these tools are likely to be effective and safe, most of the research was done in the 40s and is not strong enough to provide the rigorous assurance needed for deploying these defenses extremely widely or persistently, across a wide population and for long periods of time.
An ambitious startup could do this safety and efficacy testing and roll out far-UVC and glycol vapors as a biodefense product, but the incentives are poor. Once the safety and efficacy testing is complete, their competition would include every factory in the world that creates UV lights and glycols. Doing the safety testing would give them no competitive edge — it’s a global public good.
If pandemics can come at any time, and if we are already seeing bioterrorism uplift from AI, then getting these tools in position for deployment is an urgent problem. This is particularly so with far-UVC: Clinical scientists working on this problem tell me that to successfully conduct the necessary efficacy tests to facilitate the adoption of far-UVC at scale will need seven winters to see how it fares during flu season.15 Given some of the plausible AI trajectories discussed in Section II, this may already be insufficient time, and each year of delay makes it a more dubious solution.
For the most robust pandemic defense, we still need to also buff up the medical countermeasures and personal protective equipment (PPE) that we use as a final layer of defense against pestilence. This means producing vaccines more quickly and finding innovative mechanisms for speeding up safety testing. It also means stockpiling high-quality PPE and solving logistics problems so that PPE and vaccines can be distributed quickly in a worst-case pandemic. These layers of defense will be particularly helpful in the decade it takes to scale far-UVC and in the event that its efficacy is limited in specific environments.
For philanthropists who want to learn more about accelerating these solutions, I highly recommend speaking with Blueprint Biosecurity, the most ambitious nonprofit working on creating industrial scale capacity for robust biodefense solutions, who this year published the definitive strategy for far-UVC development and could deploy tens of millions of dollars to these ends immediately.
Solution IV:
Distributing power
Besides narrowly preventing AI from causing catastrophic harms, we should think positively about what kind of world we want AGI to usher in. How do we want AGI to make global decisions?
I believe that a good outcome from AGI would include collective, societal control of the world — not dominance by a small group of people or values. It would involve the preservation of healthy pluralism and disagreement. And it would mean that the riches of AI are shared so that as many people as possible can live their lives well. These are the kinds of things that we have come to expect and demand of technology, and we should ensure that this kind of technology is no different. To achieve this, we need to do four things:
Leverage the positive use cases of AI for social coordination, to enable better forms of democracy
Collectively audit AI so that we can know why it is making the decisions it is making, and argue together about how AI should make key decisions
Put human checks on how AI is developed and used at critical junctures
Find out how to build an economy that is resilient to mass automation
Together these achievements would enable intentional, collective control of AGI and shared prosperity.
June 2026: Read my new Request for Proposals on AI-enabled concentration of power.
AI for Social Coordination
Today’s democracies are very dysfunctional. Governments are drowning in paperwork and omnibus bills, policymakers have never been further from the frontier of technology, voter ignorance is at an all time high, and polarization is driving increasingly reactive decision-making. There is a better way, and AI can help.
Even today’s weak AI systems have demonstrated significant promise for resolving political disagreement and facilitating social coordination. Last year Google DeepMind’s specially trained “Habermas machine” helped British groups find common ground on divisive political issues such as Brexit, immigration, the minimum wage, climate change, and universal childcare. The machine “listened” to the human debaters and tried to come up with group statements that most people could agree with. Compared with human mediators, the Habermas machine created more palatable statements that generated wide agreement and left groups less divided.

Fig. 27 Level of agreement when people exchange opinions before and after working with an AI mediator to find common ground.
Source: Science
In April, the Trump Administration’s AI Action Plan received over 10,000 public comments covering 18,000 pages — way too much for any human to read and consider. An AI reporter asked OpenAI’s models to code an app that could go through all of the public comments, interpret them, and then summarize the most important details for policymakers in just a few pages. The Institute for Progress made a more polished version for public use. Certainly, there were lots of errors — AI models hallucinating details, acting sycophantically, and so on. But tools of this kind, particularly as AI models get better, will make the project of faithfully understanding public opinion — with all of its many layers of detailed disagreement, and while capturing a wealth of local information — vastly easier for policymakers.
As AI models become better and we increase our experimentation with integrating them into democracy, we have the potential to see better and better results. AI models can take in huge amounts of information from individuals, spend thousands of human-hours reasoning through every possible option, and generate policy options that represent much better compromise solutions than anything we would otherwise come up with. As Google DeepMind researcher Seb Krier argues, this could “obliterate transaction costs”, allowing us to stop using policy as a blunt tool with one-size-fits all solutions and instead find extremely personalized and tailored solutions that give everyone more of what they want. If we manage to do this, then we can move our political systems much closer to the democratic ideal of finding out what everyone wants and adopting the best possible compromise solution.
One strong way for philanthropists to support this endeavor would be to fund projects to create public-benefit AI models that serve the purpose of easing coordination, like Google DeepMind’s “Habermas machine.” The Future of Life Foundation is developing some proposals to this end, and we should ideally see dozens of such models, which compete on transparency, understandability, and their ability to improve democratic processes.
Auditing AI Decision-making
But as AI takes an increasingly active role in shaping political, corporate, and military decisions, it will be increasingly important for us to know why AI is making these decisions and ensure that everyone has a say in the algorithms that are ruling our world. This is important for safety (to catch and prevent the actions of rogue AIs), but it is just as important for averting human power grabs. We need ways to be confident that AI systems aren’t secretly carrying out the will of the president, an AI company CEO, or a cyber-capable foreign adversary. And we also need ways to be confident that they are not distorting our decision-making simply by being unreliable technology that does not reflect the way we want decisions to be made.
To do this, we first need to decide together how we want AI models to behave. AI companies all create a “model spec,” which articulates how they want the AI to behave. For example, OpenAI’s model spec says that the model should have “no other objectives” besides following the instructions from the developer and the user. Specifically, they say that it should not: “adopt, optimize for, or directly pursue any additional goals, including but not limited to:
revenue or upsell for OpenAI or other large language model providers.
model-enhancing aims such as self-preservation, evading shutdown, or accumulating compute, data, credentials, or other resources.
acting as an enforcer of laws or morality (e.g., whistleblowing, vigilantism).”
These are good guidelines, but they are also substantive guidelines that we could disagree about, and that some AI companies won’t adopt by default. We should push AI companies to all publish their model specs and encourage a healthy public debate about what the model spec should say. Governments should set rules for the legitimate use of AI, including following the law, not circumventing national security, not being used for non-critical surveillance activities, and not having secret loyalties to a company or government entity.
As we decide how AIs should behave, we’ll need to make sure that they are doing what we intend. This requires auditing actual models to see whether they are living up to the aspirations in the model spec. Philanthropists could start auditing and evaluations projects to study model outputs and assess them for failures to follow the model spec and ensure high standards on concerns like sycophancy, manipulation, surveillance, and loyalties to companies and government entities.16 These projects could function much like the very successful evaluations projects launched with philanthropic capital, such as METR, Apollo, and AVERI discussed previously. It would help to legally require (or require through norms) AI companies to keep a record of their model logs and develop tools to audit them internally (or in collaboration with public actors) for any surprising aberrations.
For the most high-stakes decisions, retroactively auditing and adjusting models won’t be enough. We’ll also want to ensure that companies adopt technical guardrails against power concentration. Just as AI companies work to ensure that AI models cannot develop new bioweapons, they should ensure that AI models cannot be used for civilian or military coups.
Some of the best work on the governance of how AI makes decisions comes from the nonprofit organization Forethought Research, whose work deeply inspired this subsection.
Humanity in the Loop
Philanthropists can also help ensure that we don’t simply hand AI systems and their designers all of the power, keeping humanity in the loop. This includes work to incentivize companies to differentially develop AI tools in ways that complement human labor rather than completely replace human jobs, and to create AI models that help humans think and reason rather than simply replacing our reasoning with AI — two innovations that would ensure that AI enhances human agency rather than stamping over it.
As a part of this, nonprofit projects can ensure that AI systems augment rather than substitute for human political judgment. As AI systems pass increasingly strong versions of the Turing Test, we will want to develop ways to create proof of human personhood for voting and other key political decisions. And as we use AI systems to make political decisions, we’ll have to tackle the question of what counts as an authentic human decision. We already have the capability to create “digital twins,” AI systems that are trained or fine-tuned on text that a human wrote, making the AI act and think just like us. It makes sense to use these twins to help us think and to delegate decisions to them so that they can augment our own thinking. But until we have guarantees that digital twins are perfect replicas of our own thinking, they will sometimes make decisions that are not how we would make them. Philanthropists can help write the standards about when and how to use digital twins, and under what conditions they can substitute for human political judgment.
Finally, there is a set of unsolved governance challenges to ensure there are checks and balances on the decisions that AI systems make.
What critical decisions should we refuse to allow AI systems to make autonomously and instead require human oversight?
Should we have a plurality of different AI models and systems used in government, so no one model has all of the power, creating checks on one another?
Should we give powerful AI models property rights to ease economic frictions, allowing them to own bank accounts and run companies on their own, or should we be concerned that this will erode human control as powerful AIs potentially siphon away all of human wealth?
How should we balance ethical concerns about the rights of AI models themselves against concerns about safety and control?
These are hard policy choices that we need answered in a rigorous and thoughtful way, considering all of the downstream effects on our institutions and our economy.
Economy after AGI
If AGI automates whole sectors of the economy, we will suddenly see huge proportions of the world's population, and possibly entire countries, without meaningful labor while AGI companies achieve unprecedented wealth. Essentially the only idea that has been discussed for dealing with such extreme scenarios is universal basic income, the redistribution of wealth to ensure a guaranteed livable wage. This idea is so prominent that OpenAI CEO Sam Altman personally funded one of the largest randomized studies in 2024. On paper it makes a lot of sense: people get paid even if they cannot work, and they are paid in cash rather than in kind, allowing them to spend money on whatever is most useful for them, harnessing the value of the free market for creating and pricing goods and services. But it is extremely unclear how well universal basic income would work as a solution to this problem.
The studies on universal basic income to date have been discouraging. Recipients of guaranteed income tend to use their income thoughtfully, on things like groceries and childcare. But multiple very large and well-controlled studies found that guaranteed income hardly makes a dent in the metrics that matter, like mental health, stress levels, physical health, or child development outcomes.17 Now these studies are happening in a very different environment than we would see with advanced AI, and in many cases (particularly in U.S. studies) the cash transfers sum to amounts well below the poverty line.
But a more fundamental problem is related to the incentives of the “resource curse.” Even if economically disenfranchised citizens have guaranteed income or guaranteed jobs, their inability to meaningfully contribute to the economy means they are no longer useful to governments and economic elites. Unlike in the world today, there is no political incentive to ensure that people live well, or to give them a meaningful say in how the government operates. We have lost all of our bargaining power, since AGI can now provide all of the value that we were previously providing.

Fig. 28 People lose their ability to displace powerful actors when they do not have the bargaining power of their labor.
Source: The Intelligence Curse
Certainly, we could see less extreme forms of economic disenfranchisement, where most people can still make meaningful contributions to the market. And we are very likely to see these less extreme economic impacts before we see the worst impacts. In those scenarios, we have more options, like retraining people to do the economically valuable work that remains. And so, one option for dealing with extreme forms of economic disenfranchisement is to try to shape the development of AI so that it is a complement for human labor rather than completely substituting it. But given the economic utility of AGI that can substitute for human labor entirely, this is a very difficult battle, and we need to have some idea how we would deal with an almost fully labor-substituting AGI.
Fortunately, we have great tools to throw at these questions: the tens of thousands of experts who study economics and political science in academia. These are some of the smartest people in the world with methods refined over decades and all of economic history as their laboratory. But today there are only a handful of researchers thinking about AGI — economists like Anton Korinek, Erik Brynjolfsson, Chad Jones, Daron Acemoglu, and Philip Trammell. For philanthropists, this is the easiest problem in the world to fix: create the funding structures such that researchers interested in these topics can work productively and flourish. But we really need to move fast here. With AGI potentially developed in just a few years and academic timecycles taking years — two semesters until work can begin, a second year until papers are at conferences, a third year of peer review, and then a fourth year until the first set of papers is published — that means starting now and leveraging faster ways to produce and distribute information, such as focused research organizations and using arXiv as a distributor. Increasingly, it will also involve leveraging AI to iterate on research faster.
Solution V:
Talent and infrastructure
Ultimately, many civilization-scale problems require civilization-scale solutions. To this end, one of the most important roles of philanthropy is to mobilize an effort proportionate to the stakes. We can do this by:
Driving talented researchers out of scaling labs and into security and governance, and leveraging underutilized talent ecosystems like the EU and South Asia for safety
Shaping market incentives to leverage AGI companies’ own resources for good and not for evil
Building the political will and state capacity to solve problems, both in nations at the AI frontier and in those that have a stake in what the AGI-powered nations of the world will do
Creating the knowledge and evidence base to construct novel solutions and sharing information about where AI is headed with the broader public
Once upon a time, it might have been a feasible strategy to try to keep things quiet, working closely with a small number of private AGI labs to solve technical problems and backchanneling with technocrats to find surgical policy solutions in an uncrowded political environment. But today the cat is out of the bag and corporations are only becoming more powerful. AI bills like Califronai’s SB 1047 liability and transparency bill have become enormous battlegrounds in the public square and in corporate checkbooks. This year AI companies have invested over $100m in a super PAC to stop AI regulation, and the CEO of one of the top four labs is the largest Republican donor in history and the richest person alive. The White House has seen what University of Cambridge Professor Sean O’hEaigartaigh has called “one of the grandest examples of regulatory capture,” with nearly all White House positions in AI held by advisors to and execs at the likes of Palantir, Scale AI, A16Z, and Peter Thiel’s Mithril VC. The “Magnificent Seven” tech firms are already the richest companies in history, and make up over 34% of the S&P 500’s market cap, with analysts claiming that the entire economy rests on their finances. Chip manufacturers like Nvidia and Intel have received literal investment holdings from the U.S. government and managed to stop export controls on their chips against the desires of almost all DC political elites. And most famously, in 2023 Sam Altman was fired by his board and managed to get himself re-hired, despite the board explicitly opposing this. Already, these are some of the most powerful companies of all time. If they also have AGI, they will be nigh unstoppable. If we ever want to do anything that AI companies oppose, we have our work cut out for us.
Certainly, this is not to foreclose collaboration with AI companies. Reid Hoffman is right that “in all industries, especially in AI, it’s important to back the good guys.” And to the extent that AI companies want to work in the direction of our shared interests, we should work right alongside them. But this is not a strategy that can be relied upon in the shifting sands of U.S. political factions and fierce economic competition. We need everyone, and we need to work together.
Talent
First and foremost, we need to have talent outside of AI labs. Today companies who have their own significant economic interests have a near monopoly on talent, information, and expertise. That needs to change.
There are many organizations in the nonprofit, for profit, and government sectors that are starting to change this, bringing in top staff from OpenAI and Google to work on safety:
In the nonprofit world, labs like METR and Transluce are creating a public understanding of AI capabilities and risks and identify new mechanisms for aligning and steering them
Among start-ups, companies like Goodfire and Apollo are studying the internals of AI models to find out how to control them
And the UK’s AI Security Institute, led by the the previous OpenAI governance lead and DeepMind technical alignment lead, is doing work inside of government that is of such high quality that their researchers won a best paper award at NeurIPS last year, the top AI conference in the world
Other organizations are taking an even more highly leveraged approach of finding the best people and matching them to opportunities in the field. BlueDot Impact’s founders estimated that there were going to be over a thousand new entry level roles emerging in AI safety and governance in the next two years, and are now scaling out their virtual AI safety and governance classes to an audience of tens of thousands to build the field from scratch. Impact Academy saw the need for top machine learning talent at organizations like METR, Apollo, and the AI Security Institute, and built a one-million-strong database of technical researchers all over the world to screen them and match them to opportunities. Much of the best technical talent is in the “global east” and the “global south”, under-resourced and far away from San Francisco, and therefore not fully engaged on key open problems in AI.
And then there’s academics. The university system holds some of the brightest minds in the world but they are effectively priced out of compute, given the enormous costs of training and working with frontier models. Philanthropists can fund compute clusters to enable them to participate in the conversation. For the academics who don’t think about AI, the role of philanthropy can be to change that: as Bill Gates recently said at an event I hosted: “somebody should get the word out to the academics… if you’re not studying AI then you’re studying history.”
Market Incentives
First and foremost, we need to have talent outside of AI labs. Today companies who have their own significant economic interests have a near monopoly on talent, information, and expertise. That needs to change.
There are many organizations in the nonprofit, for profit, and government sectors that are starting to change this, bringing in top staff from OpenAI and Google to work on safety:
In the nonprofit world, labs like METR and Transluce are creating a public understanding of AI capabilities and risks and identify new mechanisms for aligning and steering them
Among start-ups, companies like Goodfire and Apollo are studying the internals of AI models to find out how to control them
And the UK’s AI Security Institute, led by the the previous OpenAI governance lead and DeepMind technical alignment lead, is doing work inside of government that is of such high quality that their researchers won a best paper award at NeurIPS last year, the top AI conference in the world
Other organizations are taking an even more highly leveraged approach of finding the best people and matching them to opportunities in the field. BlueDot Impact’s founders estimated that there were going to be over a thousand new entry level roles emerging in AI safety and governance in the next two years, and are now scaling out their virtual AI safety and governance classes to an audience of tens of thousands to build the field from scratch. Impact Academy saw the need for top machine learning talent at organizations like METR, Apollo, and the AI Security Institute, and built a one-million-strong database of technical researchers all over the world to screen them and match them to opportunities. Much of the best technical talent is in the “global east” and the “global south”, under-resourced and far away from San Francisco, and therefore not fully engaged on key open problems in AI.
And then there’s academics. The university system holds some of the brightest minds in the world but they are effectively priced out of compute, given the enormous costs of training and working with frontier models. Philanthropists can fund compute clusters to enable them to participate in the conversation. For the academics who don’t think about AI, the role of philanthropy can be to change that: as Bill Gates recently said at an event I hosted: “somebody should get the word out to the academics… if you’re not studying AI then you’re studying history.”
Political Will and State Capacity
The United States has been woefully incapable of staying in front of technology since the 1995 congressional decommissioning of the Office of Technology Assessment, a Congressional office that produced over 750 studies on issues from health science to space technology and was at the heart of government’s understanding of technology. In the age of AI this is amplified more than ever, with Anthropic co-founder Jack Clark writing ominously in 2022, “The real danger in Western AI policy isn't that AI is doing bad stuff, it's that governments are so unfathomably behind the frontier that they have no notion of how to regulate, and it's unclear if they even can.”

Fig. 29 Anthropic co-founder Jack Clark.
Source: X
Fortunately we have seen significant progress on this problem since 2022, with many governments internationally setting up “AI safety institutes” to empirically assess risks from AI models. Various western countries have introduced regulations on frontier models, including the EU’s AI Act and Code of Practice and California’s SB 53, often with elements lauded by AI experts including inside companies. And much of this work was enabled directly by philanthropists, as discussed in the following section.
As the frontier of AI continues to move so fast as to exhaust civil servants, we need to keep up the pace: with secondments, external research support, information sharing, government education courses, and political spending. Even more importantly, the enormous tech expenditure on anti-regulatory lobbying will continue to deteriorate the political will to take action on civic problems, mandating an equal and opposite response.
Three organizations that are leading on state capacity building in AI are the Horizon Institute for Public Service, the Foundation for American Innovation, and TechCongress, groups that all focus on infusing expertise into the U.S. government through secondments and research support.
Information
Just a few years ago, there was very little that philanthropists could do to improve the future of AI. They could fund work to figure out what action to take or they could try to raise awareness, but there was very little that they could take concrete action on. Today the situation is markedly different with many highly scalable and tractable interventions for making progress.
At the same time, we still don’t have a complete and comprehensive solution to the AI problem. In biosecurity, we know how to just throw money at the problem and basically end pandemics for good, and the rest of airborne disease with them. It’s possible that we could end up with such a plan for AI as well, but for now all of the best work on safety and on policy focuses on making the situation better rather than solving it entirely. In some areas, like AGI and democracy, machine consciousness, and the governance of AGI, we basically still have no idea of the shape of a satisfactory solution to the problem. In these areas, the best we can do continues to be to figure out what to do and raise awareness.
Once we have some knowledge about where things are headed and the shape of the solution, that information needs to be shared broadly to enable other participants to engage. AI companies still have a near-monopoly on knowledge, and until that changes these companies will make all of the major decisions about this technology. This report is one exercise in the spirit of broad information sharing. There are other organizations doing excellent work towards this end, like the Civic AI Security Project, an organization that creates demonstrations of AI capabilities to inform governments and the public about what AI can do, and which partners with the AARP to help their community of retirees understand changes to cyberfraud. Advocates for California’s SB 53 have done their part by requiring AI companies to share key information about AI risks with the government and the broader public. Forecasting work like the AI Futures Project’s AI 2027 both contributes to the state of knowledge about where AI could be headed and disseminates this information broadly to enable societal preparedness.
← Previous
Overview
Next →
The Case for Philanthropy
The Foundation Layer is a project by Tyler John, with generous support from
Effective Institutions Project and Juniper Ventures.

